일단 기본 테이블 및 데이터 생성.
-- Table: public.employeedetails
-- DROP TABLE public.employeedetails;
CREATE TABLE IF NOT EXISTS public.employeedetails
(
empld character varying(100) COLLATE pg_catalog."default",
fullname character varying(100) COLLATE pg_catalog."default",
managerid character varying(100) COLLATE pg_catalog."default",
dateofjoining character varying(100) COLLATE pg_catalog."default",
city character varying(100) COLLATE pg_catalog."default"
)
TABLESPACE pg_default;
ALTER TABLE public.employeedetails
OWNER to postgres;
이제는 테스트할 데이터 Insert
INSERT INTO public.employeedetails(empld, fullname, managerid, dateofjoining, city) VALUES ('121', 'John Snow', '321', '01/31/2014', 'Toronto');
INSERT INTO public.employeedetails(empld, fullname, managerid, dateofjoining, city) VALUES ('321', 'Walter White', '986', '01/30/2015', 'California');
INSERT INTO public.employeedetails(empld, fullname, managerid, dateofjoining, city) VALUES ('421', 'Kuldeep Rana', '876', '27/11/2016', 'New Delhi');
postgreSQL 현재시간 확인하는 쿼리
--an SQL query to find the current date-time.
SELECT NOW();

두개 문자열 합치는 쿼리.
CONCAT() 함수를 사용하면 아주 간편하고 이거 생각보다 실무에서 쓸일이 많다.
SELECT empld, managerId, CONCAT(empld, managerId) as NewId
FROM EmployeeDetails;

중복된 데이터가 있는지 확인하는 경우.
사실 실무에서는 중복된 데이터가 저장되는 것 자체가
잘못된 로직이기에 이런 쿼리를 쓰는경우는 극히 드물다.
Group by, Having까지 쓰면 성능도 안좋고...
이론으로만 주로 보는 내용.
SQL query to fetch duplicate records from EmployeeDetails (without considering the primary key – EmpId).
SELECT fullname, managerid, dateofjoining, city, COUNT(*)
FROM EmployeeDetails
GROUP BY fullname, managerid, dateofjoining, city
HAVING COUNT(*) > 1;
이번에는 Limit offset 확인할 차례.
역시 테스트할 테이블 생성
-- Table: public.employ
-- DROP TABLE public.employ;
CREATE TABLE IF NOT EXISTS public.employ
(
id integer,
name character varying(100) COLLATE pg_catalog."default",
performance integer,
salary integer
)
TABLESPACE pg_default;
ALTER TABLE public.employ
OWNER to postgres;
그리고 테스트할 데이터도 생성
INSERT INTO public.employ(id, name, performance, salary) VALUES (1, 'Mary' , 101, 55000);
INSERT INTO public.employ(id, name, performance, salary) VALUES (2, 'John' , 103, 66950);
INSERT INTO public.employ(id, name, performance, salary) VALUES (3, 'Suzi' , 104, 89250);
INSERT INTO public.employ(id, name, performance, salary) VALUES (4, 'Gracia' , 105, 118800);
INSERT INTO public.employ(id, name, performance, salary) VALUES (5, 'Nancy Johnson', 103, 97850);

먼저 LIMIT 한건만 나오게 할때 사용한다.
아래 쿼리는 기본 오름차순(ASC)를 역순으로
즉 급여 역순이니 제일 급여가 높은 사람을 보여주는 쿼리가 된다.
SELECT * FROM employ ORDER BY salary DESC LIMIT 1

47) Write the SQL query to get the third maximum salary of an employee from a table named employees.
이제 OFFSET까지 붙여보겠다.
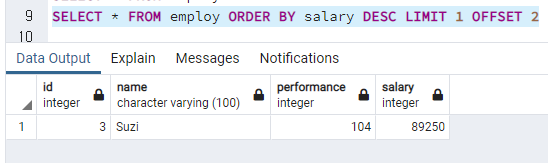
SELECT * FROM employ ORDER BY salary DESC LIMIT 1 OFFSET 2
제일 급여 높은사람에서 2번째 뒤니 3번째로 급여가 높은 사람이 추출됨.
유난히 외국에서는 이런 쿼리를 좋아하는 것 같음
많은 예시가 보임.
이런 방법도 있네요.
조회하면 똑같이 세번째 연봉 많은 사람이 나와요.
SELECT salary
FROM
(SELECT salary
FROM employ
ORDER BY salary DESC
LIMIT 3) AS Temp
ORDER BY salary LIMIT 1;

아래는 원문이고 클릭하면 페이지로 넘어갑니다.

'그냥 사는 이야기' 카테고리의 다른 글
| [이마트 와인 추천] 투핸즈 엔젤스 쉐어 Two Hands Angels' Share Shiraz 2020 (0) | 2021.11.25 |
|---|---|
| Suits Season5 EP01,02 | 슈츠 시즌5 EP 01,02 로 영어공부 (0) | 2021.11.14 |
| SQL Quiz N번째 높은 급여 찾기 (0) | 2021.10.19 |
| not exists 와 except 생물학 문제 (0) | 2021.10.18 |
| Inner Join, Outer Join (0) | 2021.10.17 |




댓글